Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, Instruction tuning significantly enhances task generalization re-emphasizing the value of supervised multitask learning.
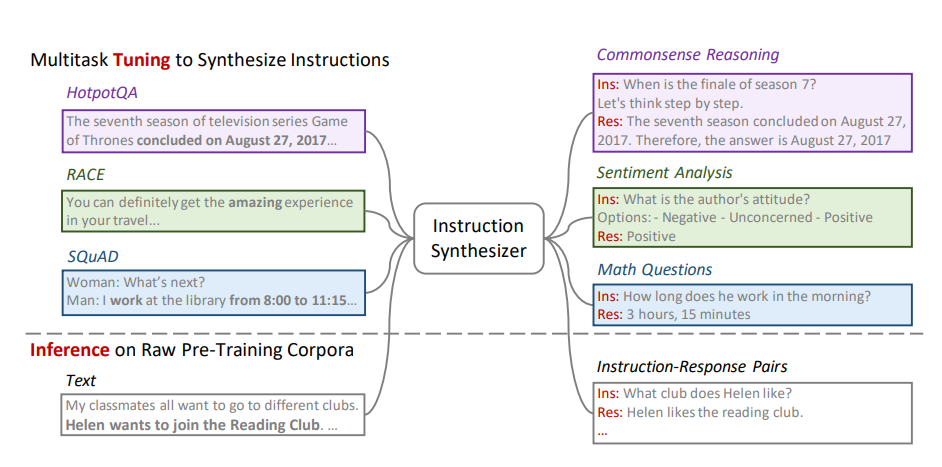
So can we utilize supervised multitask learning during pre-training ? To explore this researcher have introduced Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models (typically with 7B parameters). Instead of directly pre-training on raw corpora, Instruction PreTraining augments the corpora with instruction-response pairs generated by an instruction synthesizer, then pretrains LMs on the augmented corpora.
During tuning, the instruction synthesizer learns to generate instruction-response pairs for a given raw text. The tuning data are curated to be highly diverse, enabling the synthesizer to generalize to unseen data. During inference, this tuned instruction synthesizer is used to generate instruction-response pairs for raw texts from pre-training corpora. This efficiency allows scale up task synthesis: augmenting the raw corpora with 200M instruction-response pairs across more than 40 task categories.
For evaluation, experiments were conducted in both general pretraining from scratch and domain-adaptive continual pre-training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3- 70B.
Paper : https://arxiv.org/pdf/2406.14491